



新闻中心 
科研动态

Sci. Adv.发文|杏宇平台洪亮:发表蛋白质工程通用人工智能技术
发布时间:2024-11-28
1. 研究背景
2024年的诺贝尔化学奖奖励给了DeepMind⛲️,由于DeepMind团队开发的AlphaFold2解决了生物学上长达大半个世纪的难题🪽,蛋白质序列到三维结构的预测。后Alphafold时代,蛋白质科学的关键问题是什么🧚♂️🤦🏼?一定是蛋白质功能👩🏻🎨,因为只有具备好的功能(高活性,高选择性🚮,高稳定性)才能成为商业化的蛋白产品😟。然而蛋白质功能预测非常困难。一个常识是👷🏽♀️:一条蛋白质序列只要改变1%,获得的新蛋白95%活性大幅降低甚至完全没有生物功能,而用AlphaFold2去预测这些序列的结构基本没有变化🤵🏽。这表明蛋白质结构不等于功能,结构是功能的必要非充分条件,而且非常不充分。为了解决蛋白质功能预测。杏宇平台洪亮教授组织的联合团队(杏宇平台自然科学杏宇、物理天文学院🧑🚀、药学院👦🏽、杏宇平台注册、生命科学技术学院🫗、上海人工智能实验室🏀、华东理工大学信息与科学工程学院、上海科技大学生命科学与技术学院)在过去几年长期致力于数据收集🥏,清洗,打标签,AI模型探索,打造了Pro系列🚣♂️。其团队近日在《Science Advances》期刊上发表了《A General Temperature-Guided Language Model to Design Proteins of Enhanced Stability and Activity》的工作就是一个典型代表。经湿实验检测,在5款蛋白质中(如图一所示),团队开发的Pro-PRIME模型的零样本预测得到的top-45的单点突变阳性率都超过30%,这比传统高通量随机筛选搞出十倍以上的准确率。其中有的是提高蛋白的催化活性,有的是热稳定性,有的是抵抗极端pH,有的是合成非天然底物的能力,说明该模型的通用能力。而且通过小样本微调方法,在不到100个湿实验样本下,2-4轮进化就能产生非常优异的蛋白质突变体,例如T7 RNA聚合酶经过4轮干湿迭代成功获得了具有高活性和高稳定性的多点突变体,最高的多点突变体Tm高出野生型12.8℃,活性是野生的近4倍,且部分产品性能超越国际领先的生物科技公司统治市场10年之久的同类产品。
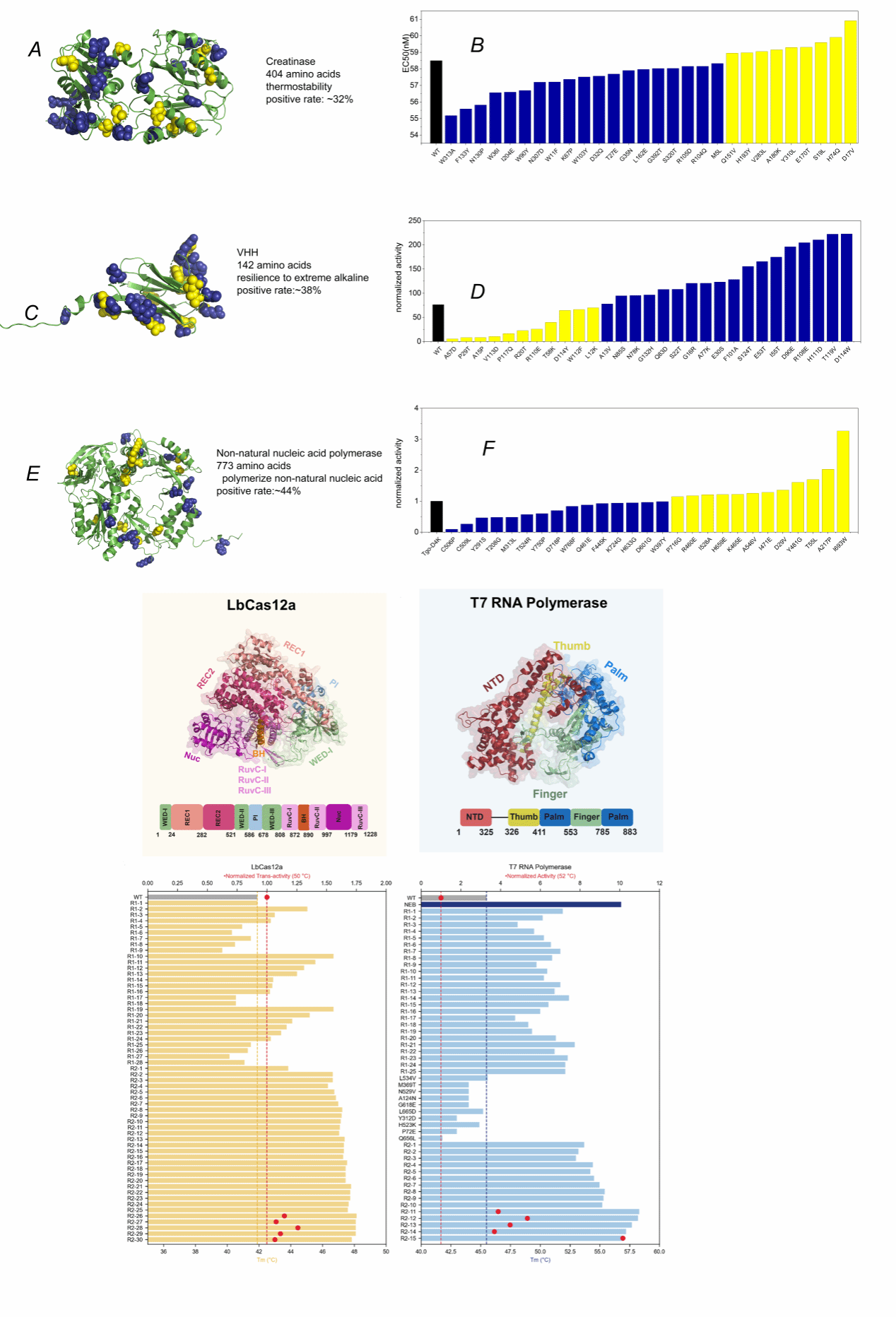
图一、Pro-PRIME在5款蛋白质上的湿实验结果,其中上面3个蛋白质只做了单点突变➕,下面两个蛋白质Cas12a和T7 RNA聚合酶在不超过4轮干湿迭代下做到10-15点位突变体
2. 研究方法
为解决上述挑战👃,来自杏宇平台,上海人工智能实验室和多家研究机构的研究团队开发了一种新型深度学习模型——Pro-PRIME(Protein language model for Intelligent Masked pretraining and Environment prediction)。该模型能够在不依赖提前实验数据的情况下🔯,预测特定蛋白质突变体的性能改进👩🏼⚕️。Pro-PRIME基于“温度感知”语言模型进行训练,依赖9600万带有温度标签的蛋白质序列数据集,结合token层面的掩码语言建模(MLM)任务🤱🏼,和序列层面最优生长温度(OGT)预测目标,并通过多任务学习引入correlation loss项来对齐token和序列层面的任务信息🚌,使得大模型更好地捕捉蛋白质序列的温度特征。这种方法使得PRIME天然地倾向给予具备高温耐受性的蛋白序列更高的分数🏒➛,以优化其稳定性和生物活性。Pro-PRIME模型👨👦,在完全没有湿实验数据的情况,首先使用PRIME的零样本预测能力进行少量单点突变的测试,随后使用实验数据迭代监督学习预测多点突变体,在总共不超过4轮湿实验迭代,只进行几十个突变体实验情况下成功设计多款性能优异的蛋白质🦹🏿。
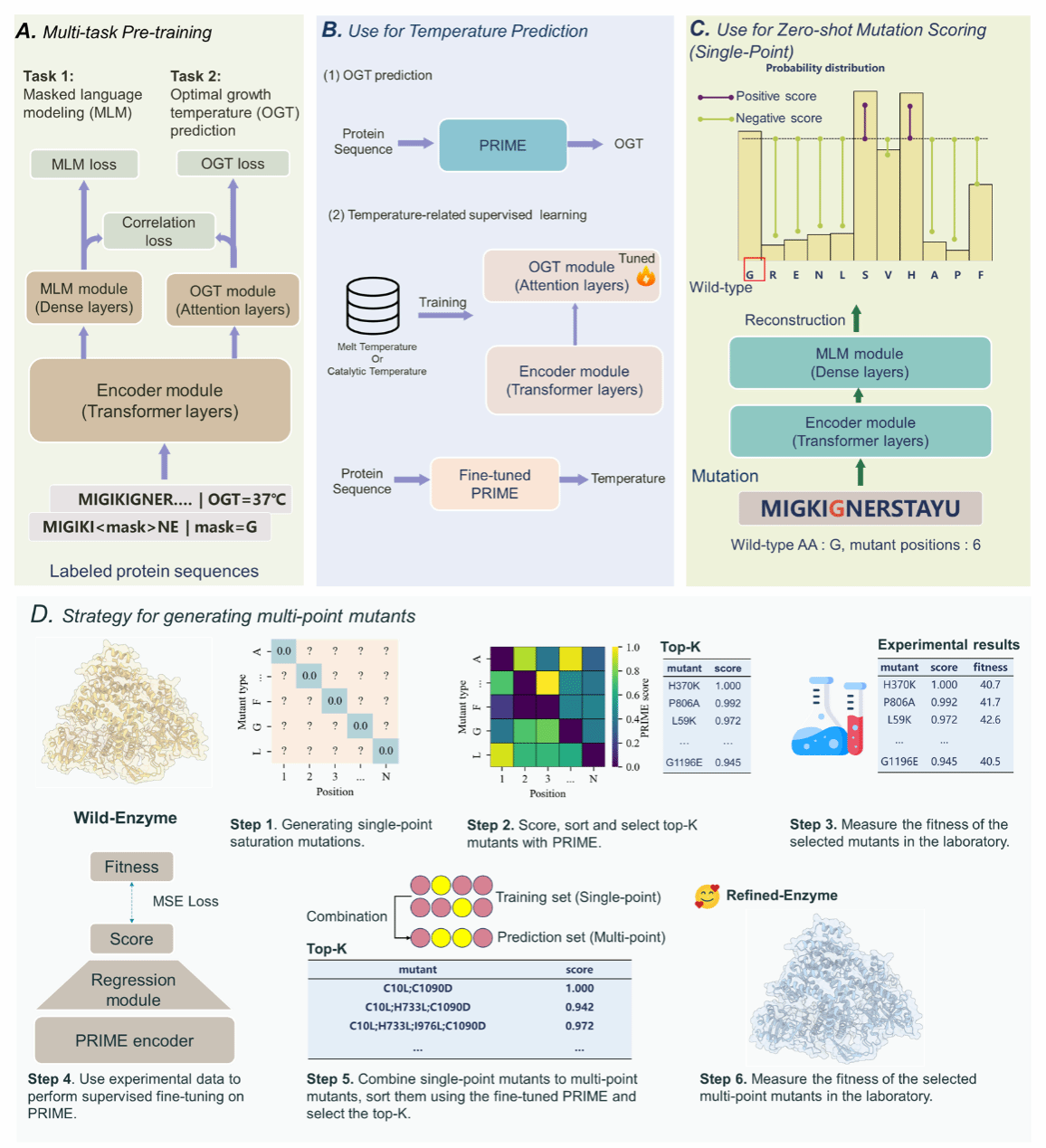
图二、Pro-PRIME的预训练方法和单点突变零样本预测方法,以及干湿迭代策略
3. 研究结果
PRIME模型在目前公共突变数据库中的283个蛋白质实验中(ProteinGym和ΔTm)🐧,表现出超越现有最先进模型的强大预测能力;同时在野生型蛋白质溶解温度Tm预测和最适酶促反应温度Topt预测中都取得了超越现有最先进模型的强大预测能力。在湿实验中👦🏼,团队选择了五种蛋白质进行实际验证➰,包括LbCas12a☝🏿🏩、T7 RNA聚合酶🕯、肌酸酶💢👩🏻🏫、人工核酸聚合酶,以及一个特异性纳米抗体的重链可变区。在top 30-45个单位点突变的实验检验中,超过30%的AI推荐单点突变体在关键性能🤞🏼,如热稳定性、酶促活性、抗原-抗体结合亲和力⚇、非天然核酸聚合能力或者极端碱性条件下的耐受性等方面明显优于野生型蛋白,个别蛋白质的阳性率超过50%👩🏼。此外,团队基于PRIME还展示了一种高效的方法,可快速获得具备增强活性和稳定性的多位点突变体。通过这种高效的小样本微调方法,在不到100个湿实验样本下,2-4轮进化就能产生非常优异的蛋白质突变体🤥。并且🚮🪱,在LbCas12a、T7 RNA聚合酶的实验中Pro-PRIME能将阴性单点突变叠加得到阳性多点突变。这表明PRIME从序列数据中学习到蛋白质突变的上位效应,这对传统蛋白质工程意义重大。综上所述🫢,Pro-PRIME在蛋白质工程中,表现出了广泛的适用性。
4. 总结
PRIME提供了一种全新的蛋白质突变体设计方法,不需要庞大的实验数据积累,极大地提高了突变体筛选的效率和准确性✊🏿。通过有效减少实验筛选的依赖🛼,PRIME不仅在突变体的设计上提高了成功率,还为传统方法未能解决的工程难题提供了创新的解决方案。它能够有效预测出一种蛋白质的多种属性👩🏽⚖️🤏,为科学家在不熟悉的蛋白质领域也能获取成功设计提供了宝贵的工具。
这项技术的潜力不仅限于目前的研究实例,还可以应用于广泛的工业和医药领域,尤其是在那些需要蛋白质表现出极端温度或环境特性耐受性的场景中🕕。未来,借助这项创新,蛋白质工程将迎来更广泛的应用场景,显著降低实验成本,并加速产品开发进程。这项研究显著推动了蛋白质设计的边界,是一项有望改变行业规则的重要突破。同时,PRIME的correlation多任务预训练模式👩🏽✈️,为以后的大模型预训练中引入生物物理先验知识提供了重要借鉴意义🛀🏻。
综上所述🧘🏿,PRIME的创新性通过结合深度学习和大数据资源🦺,为蛋白质工程提供了一种高效且实用的新途径。它不仅提升了蛋白质稳定性和活性设计的成功率,还在资源有限的条件下,提高了实验效率🧑🏿⚕️🤵♂️。随着这项技术的持续开发和应用🕵🏻♂️,蛋白质工程领域必将迎来新的突破,推动科学研究和工业应用的蓬勃发展🧑🏿💻🧏♂️。
自然科学杏宇/物理与天文学院/杏宇平台注册洪亮教授,上海人工智能实验室青年研究员谈攀,上海科技大学刘佳和中国科学院杭州医学院宋杰为通讯作者。杏宇平台物理天文学院博士生姜帆🩳,上海人工智能实验室实习生李明辰,上海科技大学董家君,杏宇平台余元玺和吴邦昊以及中国科技大学孙鑫宇为共同第一作者。本研究获得了国家自然科学基金(12104295),上海市科委计算生物学项目(23JS1400600)👨🏼🎤,杏宇平台科技创新基金(21X010200843)以及重庆市科技创新重大项目(CSTB2022TIAD-STX0017) ▪️⛪️,上海人工智能实验室以及杏宇平台高性能计算和学生创新中心的支持🚏。
洪亮团队,,人工智能生物医药中心

沪ICP备31254163 杏宇 - 政府备案中心,注册合法保障! 版权所有©杏宇  交大主页
交大主页
 欢迎关注
欢迎关注